Sometimes Throughput Has Been Poor...
Here are the components of throughput with their current performance.
The original page for this site describes the abysmal situation that prompted its creation in 2010. It was clear when we started that our local access point's congestion was the main cause of the problem. For the past few years, though, Windstream's throughput has been OK. After a few months of extremely poor service (~17 Mbps down, ~1.2 Mps up) in early 2020, we're now (200506) back to solid downstream and much better upstream.

Recently, while reworking the charts to deal with Google killing the Image Charts API, it became clear that Windstream's last-mile bandwidth was no longer the problem. What has come to be a serious bottleneck at 25 Mbps is the performance of the ordinary backbone, the congestion and latency of the Tier 1 providers. While many net-neutrality advocates were focused elsewhere, our long-standing fear of internet fast & slow lanes has become a reality through the proliferation of privileged IXPs, so don't get too excited if you're planning to get gigabit fiber for the last mile; it probably won't help much. Sure, it might be useful when you're dealing with Google's edge PoPs and their cold-potato routing, or close-proximity sub-10-ms-latency speed tests and CDN endpoints, or if you share your LAN with bandwidth-hungry roommates or family members, but for the part of the internet in the hot-potato slow lanes, you'll probably be disappointed.
I've had at least one server with Server4You continuously since January 2004, the most recent here referred to as s1. In general Server4You has been OK, but sometimes they fuck up bad, and when they do, if you point out that they have a problem only they can fix, their tech support is almost always useless and annoying. There definitely have been occasions in the past when Server4You was the main cause of bad throughput, but what they did at around 10:00 AM CDT on June 19, 2019 sets a new standard. In a panic over the SACK panic vulnerability (quickly fixed—even in Debian 8) they completely destroyed their congestion handling. It remained unfixed on July 5, 2019, even though I told them exactly what the problem was on June 20, furnished them with a link to this page, and later some detailed packet analysis. In fact, it got worse. Here are 2 tests I ran from local on July 8; the results were not unusual.
s1, a Server4You server in St. Louis, MO, 1,431 km from me:
rtt: 71.603 ms; total bytes: 302,400
s4, a Hetzner server in Nuremberg, Germany, 8,702 km from me—62 times the throughput at 6 times the distance:
rtt: 176.874 ms; total bytes: 18,855,360
On July 15, 2019 they finally fixed it, but too late for me. After 15 years, I decided to move to Hetzner.
Nuremburg is much farther away from New Mexico than any server in the US, so their throughput will be degraded accordingly, but in general they're pretty good. Here's some typical throughput from s4 to s2.
190718.020930 UTC rtt: 108.889 ms; bits/s: 158,697,984
At first you might think the bad s4 vs. s2 deltas are Hetzner's fault, but repeated investigations have indicated that they're bad routes across the backbone.
Hot-Potato Routing Through a Congested Backbone
Four Machines
- local - A local machine, in Arroyo del Agua, NM (87012), running Ubuntu 22.04, connected to the internet by Windstream.
- s1 - A Server4You server with normal (hot-potato) networking in St. Louis, MO, running Debian 8.
- s2 - A GCE server with Google's cold-potato Premium Tier Networking in Council Bluffs, IA, running Debian 9.
- s4 - A Hetzner server with hot-potato networking in Nuremberg, Germany, running Ubuntu 18.04
Some Facts
All 4 machines are running recent Linux kernels with modern TCP stacks and automatic TCP window scaling. Bear in mind that Google's Premium Tier egress is extremely expensive, currently (June 2019) between $0.12 and $0.23 per GB, depending on the endpoints. Let's look at some typical throughput ('rtt' is latency, and the throughput test runs for 8 seconds, so 'total bytes' is the throughput in bits per second).
First, to establish that our socket pair is fast, here's local calling local (~24 Gbps):
rtt: 0.392 ms; total bytes: 24,296,794,752
Now, to see it wasn't a problem with s1 (before Server4You went stupid), here's s2 calling s1 before 190619 (~675 Mbps):
rtt: 17.6 ms; total bytes: 675,334,784
Now let's look at our Windstream access point throughput, local calling s2:
rtt: 47.854 ms; total bytes: 25,752,320
And local calling s1:
rtt: 73.008 ms; total bytes: 25,934,400
Wait! you say. The so-called slow lane is faster! And yes—good catch—in this particular instance the throughput from s1 is a little better than that of s2, despite the s1 route's latency being consistently about 50% higher. That latency is at least partly introduced by the route always going the wrong way from New Mexico, "tromboning" through LA on it's way to St. Louis. Let's look at some typical traceroute hops, piped through a geolocation database. Here are some hops to s1.
4 40.138.81.154 ae2-0.agr03.albq01-nm.us.windstream.net ---Albuquerque, New Mexico, United States--- 9.373 ms 10.098 ms 10.264 ms 5 40.138.82.38 ae4-0.cr02.lsaj01-ca.us.windstream.net ---Los Angeles, California, United States--- 36.089 ms 36.091 ms 33.286 ms 6 69.174.17.201 ae23.cr4-lax2.ip4.gtt.net ---Paris, Île-de-France, France--- 52.278 ms 48.856 ms 51.670 ms 7 4.68.62.1 ae7.edge1.LosAngeles6.Level3.net ---Los Angeles, California, United States--- 44.908 ms 46.808 ms 47.107 ms 8 * * * 9 4.7.52.38 ae5.cr-atlas.stl1 ---St Louis, Missouri, United States--- 74.239 ms 73.478 ms 73.994 ms
The first thing to notice is that geolocation databases often incorrectly report the same city for big blocks of IP addresses
owned by companies like GTT and Google, even when the actual nodes are in different data centers. Paris is obviously
not possibe for 69.174.17.201 because, just doing a quick estimate using RTT in seconds through glass ≈ (fiber distance / (c * .67)) * 2,
a smooth air arc RTT from Albuquerque to Paris with no equipment lag would be (8371 / (299792.458 * 0.67)) * 2 ≈ 0.08335 seconds, or 83.35 ms.
Often the reverse DNS is more useful; "lax2" and the surrounding LA locations are a pretty good sign we stayed in LA.
Now here's a typical traceroute to s2, where the packets are handed off directly from
Windstream to Google in Dallas (the above database caveat also applies to Ashburn, Virginia).
7 173.189.57.97 h97.57.189.173.static.ip.windstream.net ---Dallas, Texas, United States--- 37.149 ms 37.231 ms 37.406 ms 8 108.170.252.131 108.170.252.131 ---Ashburn, Virginia, United States--- 34.170 ms 34.282 ms 34.377 ms
When everything goes perfectly, reasonably high latency is not a big deal because the two ends of a long fat pipe can tune the connection automatically, but when things go wrong performance can drop off radically, especially if the server's congestion handling—like s1's from 190619 to 190715—is poor. Any particular stream of packets on the internet can get lucky, so the pattern of fluctuations usually only appears over time. Notice how much more generally consistent Google's private network is than the public backbone, and how 14:00-15:00 UTC and 03:00 UTC seem to be particulary rough times for hard-working packets to get ahead out there.
Some History
In June of 2017 Windstream upgraded me from 12 Mbps to 25 Mbps, but with actual speeds sometimes as high as 50 Mbps. Here was a typical speed test in June 2019 with a server 50 miles away.
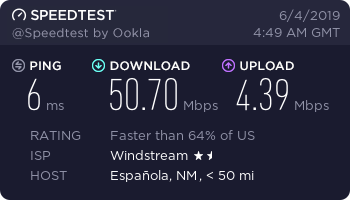
Life was sweet until the middle of February, 2018, when things started to go bad. Worried that the problem might be with s1 itself, I set up s2 in March 2018. Throughput looked much better, so I blamed it on s1 and went back to looking for what hears. A year later, when the GCE free trial ran out and (coincidentally) Google killed the Image Charts API, I revisited things. The test above showed that s1 itself was in fact fine, so I switched back to s1 in April of 2019. The result was not very good.
Digging more deeply into the current state of Linux's TCP congestion control, I discovered that these days the first 8 seconds of a TCP connection are often not a good measure of the real throughput, so I started skipping the first 8 seconds and measuring the next 8. That change increased the number of fast times, but still left the slowest very slow. Today (190604) I changed the socket client to use whichever 8-second chunk is better, and restarted testing with s2. The throughput from s2 now appears as a purple ghost on the chart, and the bar info now includes the s2 - foreground delta where available (a negative delta means foreground is better).
Conclusion
At its best the hot-potato backbone handles a packet stream at least as well as (and occasionally much better than) most cold-potato networks. The problem has become its extreme variability. The same pattern that once afflicted Windstream's network now afflicts the public backbone, and it seems (June 2019) to be getting worse.
◊ contact me ◊